





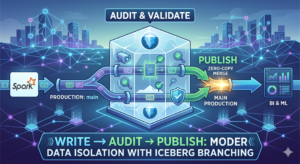
Stop Breaking Production Data Pipeline: Implementing Write-Audit-Publish (WAP) with Spark and Apache Iceberg
Learn how to implement the Write-Audit-Publish (WAP) pattern in your data pipelines using Apache Iceberg branching and PySpark to guarantee data quality.

The Data Modeling Wars: Inmon vs. Kimball vs. Data Vault
Confused by data modeling? We break down the key differences between Inmon, Kimball, and Data Vault architectures so you can choose the right strategy for your data warehouse.

Apache Spark 4.1 is Here: The Next Chapter in Unified Analytics
Apache Spark 4.1 is here. Discover how Real-Time Mode (RTM), Declarative Pipelines, and Arrow-Native UDFs are transforming data engineering and PySpark performance