






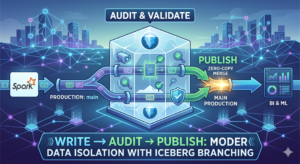
Stop Breaking Production Data Pipeline: Implementing Write-Audit-Publish (WAP) with Spark and Apache Iceberg
Learn how to implement the Write-Audit-Publish (WAP) pattern in your data pipelines using Apache Iceberg branching and PySpark to guarantee data quality.

The Data Modeling Wars: Inmon vs. Kimball vs. Data Vault
Confused by data modeling? We break down the key differences between Inmon, Kimball, and Data Vault architectures so you can choose the right strategy for your data warehouse.

Apache Spark 4.1 is Here: The Next Chapter in Unified Analytics
Apache Spark 4.1 is here. Discover how Real-Time Mode (RTM), Declarative Pipelines, and Arrow-Native UDFs are transforming data engineering and PySpark performance
Thank You for your insights on Apache Airflow vs Apache Nifi. A thought-provoking exploration of whether Apache Airflow is due for replacement, offering a first impression of Mage AI and its potential to reshape the landscape of workflow orchestration tools.
One notable strength is its candid assessment of the limitations and challenges associated with Apache Airflow. By acknowledging areas such as scalability, complexity, and a steeper learning curve, this sets the stage for introducing Mage AI as a potential alternative. This critical evaluation adds depth to the discussion, providing readers with a nuanced understanding of the considerations when working with Apache Airflow.
The introduction of Mage AI as a newcomer to the workflow orchestration scene adds an element of anticipation and curiosity. This offers a preliminary insight into Mage AI’s features, such as a simplified user interface and reduced complexity, potentially addressing some of the pain points associated with existing solutions.
Readers can grasp how Mage AI may impact their workflows based on tangible examples, making it easier to evaluate its potential fit within their organizations.
Presenting Mage AI as a contender for potentially reshaping this landscape. Its balanced evaluation of Apache Airflow’s challenges and the introduction of Mage AI make it a compelling read for professionals exploring innovative solutions for their workflow management needs.