
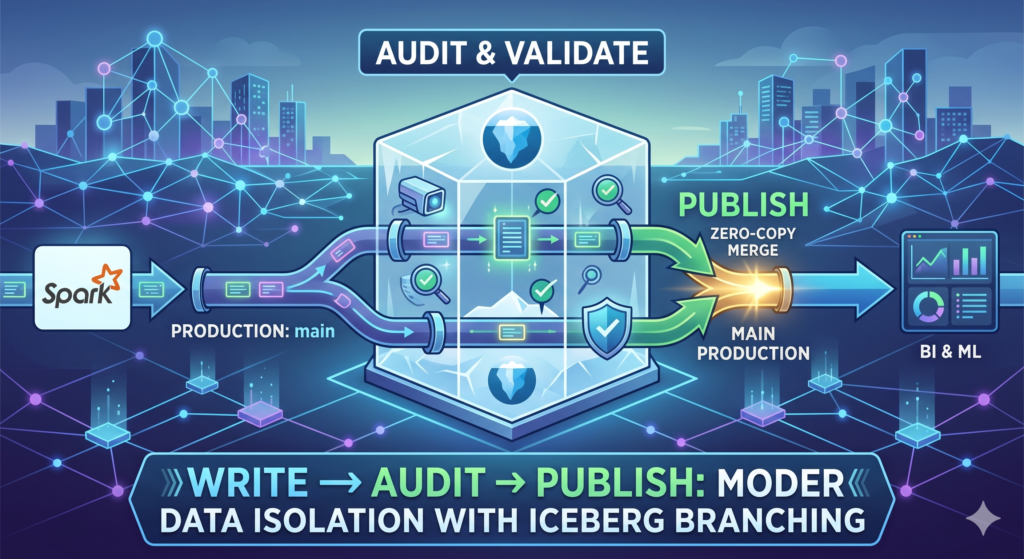
Stop Breaking Production Data Pipeline: Implementing Write-Audit-Publish (WAP) with Spark and Apache Iceberg
Learn how to implement the Write-Audit-Publish (WAP) pattern in your data pipelines using Apache Iceberg branching and PySpark to guarantee data quality.








