

Uncovering the Truth About Apache Spark Performance: coalesce(1) vs. repartition(1)
We will discuss a neglected part of Apache Spark Performance between coalesce(1) and repartition(1), and it could be one of the things to be attentive ...

Deep Dive into Handling Apache Spark Data Skew
"Why my Spark job is running slow?" is an inevitable question. We will cover how to identify Spark data skew and how to handle data ...



Apr04
5 Hidden Apache Spark Facts That Fewer People Talk About
I want to share 5 hidden facts about Apache Spark that I learned throughout my career. Those can be helpful to you to save you ...
May09
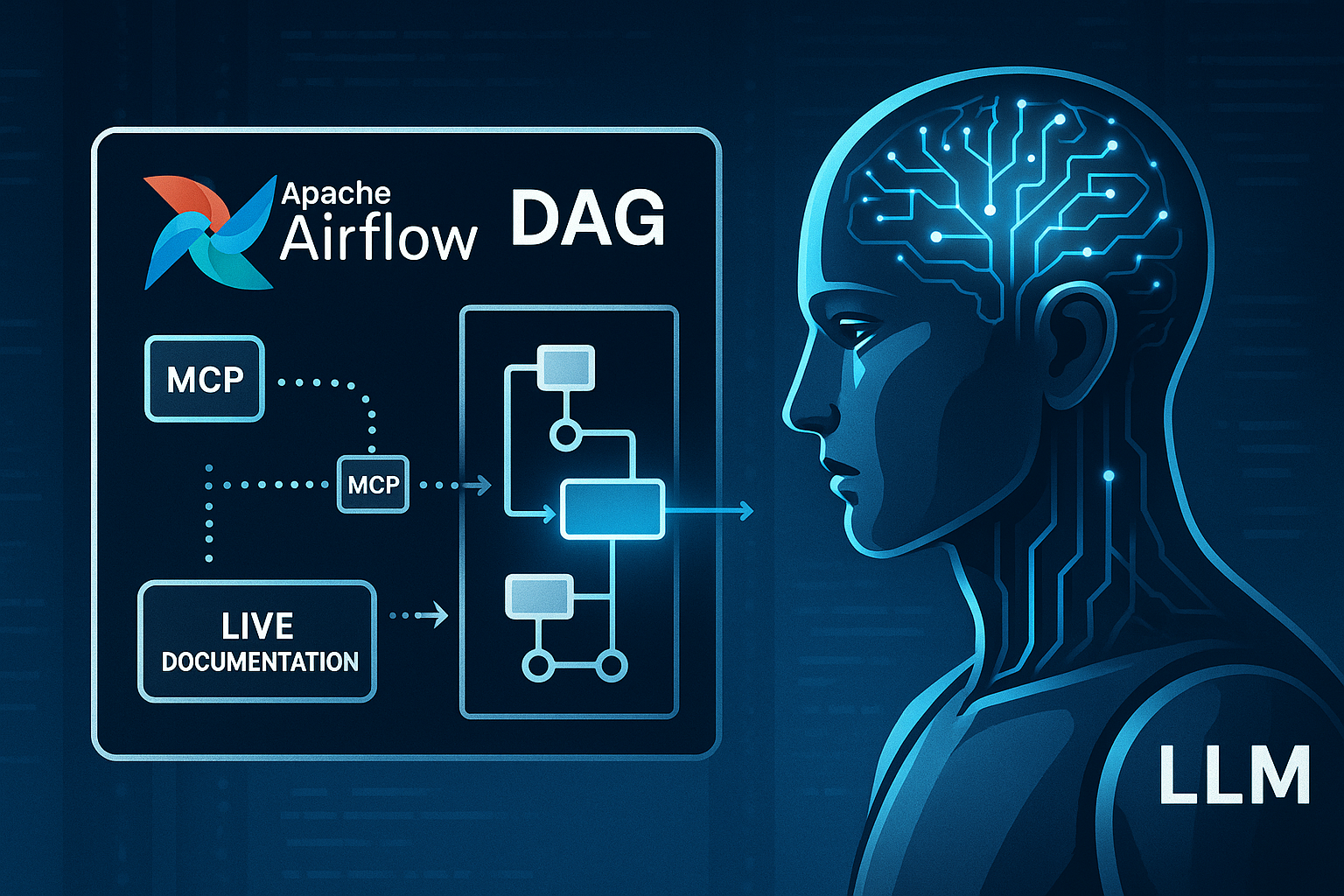
Beyond Basic Prompts: LLM + MCP Tackling Real-World Challenges—The Airflow 3.0 Auto-Update Example
Learn how LLM + MCP synergy revolutionizes complex tasks. An Apache Airflow 3.0 case study demonstrates auto-updating DAGs and overcoming AI limitations.

Feb09
I Built a Game By Using Streaming Data: A Fun Way for Data Visualization
Data visualization has always been a delightful area for me to work as a data professional. Visualizing data is like an art. Can I visualize ...