

Get the definitive handbook for manipulating, processing, cleaning, and crunching datasets in Python. Updated for Python 3.10 and pandas 1.4, the third edition of this hands-on guide is packed with practical case studies that show you how to solve a broad set of data analysis problems effectively. You'll learn the latest versions of pandas, NumPy, and Jupyter in the process.
Written by Wes McKinney, the creator of the Python pandas project, this book is a practical, modern introduction to data science tools in Python. It's ideal for analysts new to Python and for Python programmers new to data science and scientific computing. Data files and related material are available on GitHub.
- Use the Jupyter notebook and IPython shell for exploratory computing
- Learn basic and advanced features in NumPy
- Get started with data analysis tools in the pandas library
- Use flexible tools to load, clean, transform, merge, and reshape data
- Create informative visualizations with matplotlib
- Apply the pandas groupby facility to slice, dice, and summarize datasets
- Analyze and manipulate regular and irregular time series data
- Learn how to solve real-world data analysis problems with thorough, detailed examples


DuckDB, an open source in-process database created for OLAP workloads, provides key advantages over more mainstream OLAP solutions: It's embeddable and optimized for analytics. It also integrates well with Python and is compatible with SQL, giving you the performance and flexibility of SQL right within your Python environment. This handy guide shows you how to get started with this versatile and powerful tool.
Author Wei-Meng Lee takes developers and data professionals through DuckDB's primary features and functions, best practices, and practical examples of how you can use DuckDB for a variety of data analytics tasks. You'll also dive into specific topics, including how to import data into DuckDB, work with tables, perform exploratory data analysis, visualize data, perform spatial analysis, and use DuckDB with JSON files, Polars, and JupySQL. Understand the purpose of DuckDB and its main functions

The Polars Cookbook is a comprehensive, hands-on guide to Python Polars, one of the first resources dedicated to this powerful data processing library. Written by Yuki Kakegawa, a seasoned data analytics consultant who has worked with industry leaders like Microsoft and Stanford Health Care, this book offers targeted, real-world solutions to data processing, manipulation, and analysis challenges. The book also includes a foreword by Marco Gorelli, a core contributor to Polars, ensuring expert insights into Polars' applications.
From installation to advanced data operations, you’ll be guided through data manipulation, advanced querying, and performance optimization techniques. You’ll learn to work with large datasets, conduct sophisticated transformations, leverage powerful features like chaining, and understand its caveats. This book also shows you how to integrate Polars with other Python libraries such as pandas, numpy, and PyArrow, and explore deployment strategies for both on-premises and cloud environments like AWS, BigQuery, GCS, Snowflake, and S3.
With use cases spanning data engineering, time series analysis, statistical analysis, and machine learning, Polars Cookbook provides essential techniques for optimizing and securing your workflows. By the end of this book, you'll possess the skills to design scalable, efficient, and reliable data processing solutions with Polars.




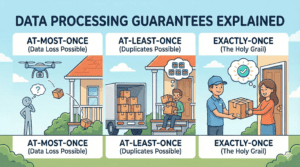
Data Processing Guarantees Explained: Exactly-Once, At-Least-Once, and At-Most-Once
Learn the difference between data processing guarantees (At-Most-Once, At-Least-Once, Exactly-Once) with simple real-world examples. Perfect for data engineering beginners

The Essential Reading List for Data Engineers: 10 Classic Books You Can’t Miss
Discover the Essential Reading List for Data Engineers: 10 Classic Books You Can’t Miss. While many free online resources are available, they often lack the depth and context needed to truly master the field. In this article, I will share ten classic books that cover everything from fundamental technical skills like Python and SQL, to more advanced topics like Apache Spark, Apache Flink, Apache Beam, Apache Airflow, Kubernetes, distributed systems, and dimensional modeling.

How to Visualize Monthly Expenses in a Comprehensive Way: Develop a Sankey Diagram in R
Personal budgeting APP like Mint/Personal Capital/Clarity only provide three limited types of charts. Have you ever wondered if charts are good enough to get better ideas on your monthly income and expense? Are there ways to visualize monthly expenses in a comprehensive way? In this article, I will share with you how to create a Sankey Diagram In R to better help you gain more insights into your personal financial situation.